

تا حالا شده بخواهید بدانید پشت پرده پیشبینیهای دقیق سایتها و اپلیکیشنها چه میگذرد؟ شناخت انواع الگوریتم برای یادگیری ماشین کلید ورود به این دنیای جذاب است. یادگیری ماشین که گاهی به اشتباه با کل هوش مصنوعی یکی دانسته میشود، در واقع نوعی مدلسازی پیشبینانه است که آرتور ساموئل آن را (یادگیری بدون برنامهنویسی مستقیم) نامید. این سیستمها دادهها را میگیرند و با هر تحلیل، باهوشتر میشوند تا خروجی دقیقتری به ما بدهند. اگر میخواهید بدانید این موتورهای هوشمند چطور از دل دادهها معجزه میسازند، ادامه این مطلب از آکادمی همراه برای شماست.
خطا: کاربر درخواست HTTP را بلوکه نمود.
یادگیری ماشین چیست؟
هوش مصنوعی به ماشینها یاد میدهد تا بدون برنامهنویسی مستقیم، از دادهها الگوبرداری کنند. برای درک بهتر، انواع الگوریتم برای یادگیری ماشین را به دستههای اصلی زیر تقسیم میکنیم:
- یادگیری نظارتشده: مانند دانشآموزی است که با کمک معلم و پاسخهای درست تمرین میکند و مدل با استفاده از دادههای برچسبدار، رابطه بین ورودی و خروجی را کشف میکند. یادگیری ماشین به عنوان یک ابزار در حوزه هوش مصنوعی، علم داده و کامپبوتر برای توسعه سیستم های هوشمند با قابلیت بهبود به صورت خودکار استفاده میشود.
- یادگیری نظارتنشده: ماشین بدون هیچ پاسخی در میان دادهها رها میشود تا خودش الگوها و گروههای مشابه را کشف کند که این روش برای بخشبندی مشتریان عالی است.
- یادگیری نیمهنظارتشده: ترکیبی از دو روش قبلی است که در آن از مقدار کمی داده برچسبدار در کنار حجم زیادی داده بدون برچسب برای افزایش دقت استفاده میشود.
- یادگیری خودنظارتشده: این مدلها بهطور خودکار از خودِ دادهها برچسب ایجاد میکنند؛ مانند پیشبینی کلمات بعدی در یک متن طولانی توسط مدلهای زبانی.
- یادگیری تقویتی: ماشین از طریق تعامل با محیط و دریافت پاداش یا جریمه یاد میگیرد؛ این فرآیند دقیقا شبیه به آموزش یک حیوان خانگی با استفاده از تشویقی است.
الگوریتم های پایه و پیشبینی های عددی
درک مدلهای خطی، سنگبنای ریاضی تمام هوش مصنوعی است. تا زمانی که متوجه نشوید ماشین چگونه یک رابطه ساده بین دو عدد برقرار میکند، درک شبکههای عصبی پیچیده ممکن نخواهد بود. این مدلها به شما کمک میکنند مفهوم خطا و بهینهسازی در انواع الگوریتم برای یادگیری ماشین را به خوبی لمس کنید و زیربنای علمی خود را تقویت نمایید.
رگرسیون خطی
رگرسیون خطی یکی از قدیمیترین و در عین حال محبوبترین مدلها برای پیشبینی مقادیر عددی پیوسته در جهان است. این الگوریتم سعی میکند با ترسیم بهترین خط ممکن میان نقاط داده، رابطه منطقی بین متغیرهای مستقل و وابسته را پیدا کند. برای مثال، اگر بخواهید قیمت یک خانه را بر اساس متراژ آن تخمین بزنید، این مدل به شما میگوید که به ازای هر متر مربع اضافه، قیمت نهایی چقدر تغییر میکند.
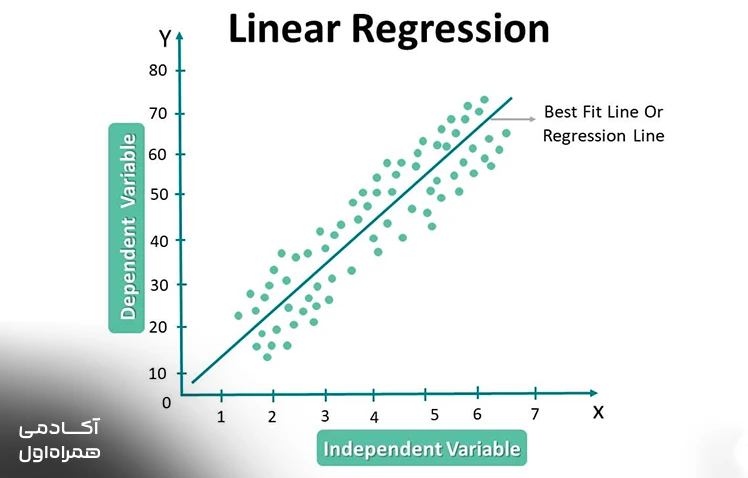
سادگی در اجرا و سرعت بالای پردازش، این مدل را به نقطه شروع ایدهآلی در اکثر پروژههای تحلیل داده تبدیل کرده است. این الگوریتم به دلیل تفسیرپذیری بالا، به تحلیلگران اجازه میدهد تا تاثیر هر عامل ورودی را به دقت روی خروجی نهایی مشاهده کنند. استفاده از این مدل در صنایع مالی و املاک بسیار رایج است و دقت خوبی در پیشبینی روندهای ساده دارد.
رگرسیون لجستیک
برخلاف نامی که دارد، رگرسیون لجستیک برای طبقهبندی استفاده میشود و نه پیشبینی اعداد به صورت خطی. این مدل احتمال تعلق یک داده به یک دسته خاص را محاسبه کرده و خروجی را با استفاده از یک تابع ریاضی بین صفر و یک قرار میدهد.
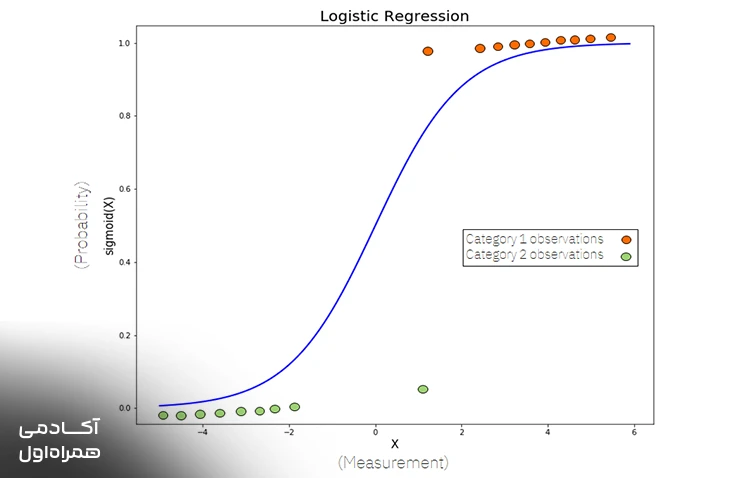
در میان انواع الگوریتم برای یادگیری ماشین، این متد ابزار اصلی بانکها و موسسات اعتباری برای تشخیص احتمال بازگشت یا عدم بازگشت وام توسط مشتریان است. اگر احتمال محاسبه شده توسط این مدل بیش از نیم باشد، سیستم نتیجه را در یک دسته قرار میدهد و در غیر این صورت آن را به دسته دیگر منتقل میکند.
خطا: کاربر درخواست HTTP را بلوکه نمود.
الگوریتم های طبقه بندی و روش های تصمیم گیری هوشمند
پس از درک اعداد، حالا باید یاد بگیرید ماشین چگونه دادهها را در گروههای مختلف تفکیک میکند. این بخش به شما یاد میدهد که هوش مصنوعی چگونه با استفاده از شرطها و مرزهای ریاضی، شبیه به یک انسان منطقی تصمیم میگیرد. تسلط بر این بخش، مهارت شما را در استفاده از انواع الگوریتم برای یادگیری ماشین برای مسائل واقعی و طبقهبندیهای چندگانه ارتقا میدهد.
درخت تصمیم
درخت تصمیم شبیه به یک فلوچارت هوشمند است که با پرسیدن مجموعهای از سوالات شرطی، دادهها را به دستههای کوچکتر و دقیقتر تقسیم میکند. هر گره در این درخت نشاندهنده یک ویژگی خاص و هر شاخه نشاندهنده یک مسیر تصمیمگیری است تا در نهایت به برگ یا همان نتیجه نهایی برسیم. این مدل به دلیل قابلیت بصریسازی بسیار بالا، برای مدیرانی که میخواهند منطق پشت تصمیمات هوش مصنوعی را درک کنند، گزینهای بینظیر است.
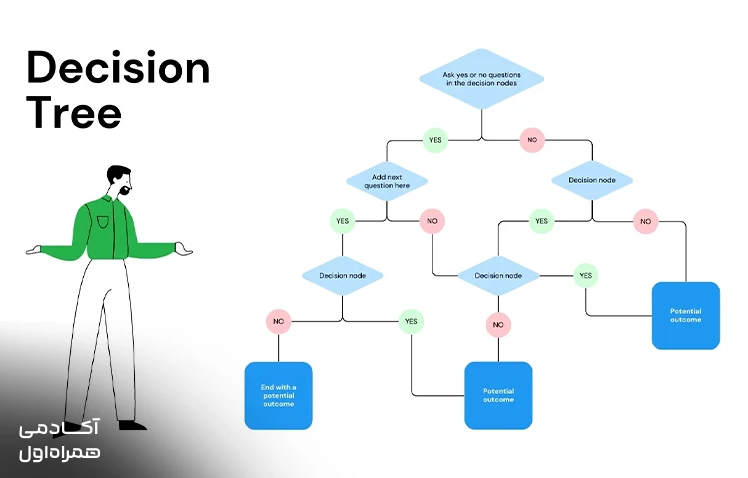
این الگوریتم به خوبی میتواند هم دادههای عددی و هم دادههای دستهبندی شده را مدیریت کند و به پیشبینیهای دقیقی برسد. به دلیل ساختار درختی، فهمیدن دلیل یک تصمیم خاص برای کاربر بسیار آسان است. با این حال، باید دقت کرد که این درختها بیش از حد بزرگ نشوند تا دقت مدل در مواجهه با دادههای جدید کاهش پیدا نکند.
ماشین بردار پشتیبان
ماشین بردار پشتیبان یک روش قدرتمند برای جداسازی دادههای پیچیده است که به دنبال یافتن عریضترین مرز ممکن بین دو کلاس مختلف میگردد. این الگوریتم با استفاده از مفاهیم پیشرفته هندسی، دادهها را به فضایی با ابعاد بالاتر میبرد تا بتواند آنها را با یک صفحه صاف از هم جدا کند.

این مدل در میان انواع الگوریتم برای یادگیری ماشین، به دلیل دقت بسیار بالایی که در مدیریت دادههای با ویژگیهای زیاد دارد، بسیار مشهور است. از این الگوریتم در تشخیص چهره، طبقهبندی تصاویر پزشکی و حتی تحلیل ساختار ژنتیک استفادههای فراوانی میشود. قدرت اصلی این مدل در زمانی است که مرز بین دادهها به راحتی قابل تشخیص نیست و نیاز به محاسبات دقیقتری وجود دارد.
نایو بیز
این الگوریتم بر پایه قضیه احتمالات بیز بنا شده و با این فرض ساده کار میکند که تمام ویژگیهای یک داده مستقل از یکدیگر هستند. با وجود این فرض سادهلوحانه، نایو بیز در طبقهبندی متن و تشخیص ایمیلهای اسپم به شکل خیرهکنندهای سریع و دقیق عمل میکند. این مدل به دلیل نیاز به دادههای آموزشی کم و سرعت پردازش فوقالعاده، برای سیستمهای تحلیل در لحظه و پردازش زبان طبیعی بسیار مناسب است.
در لیست انواع الگوریتم برای یادگیری ماشین، نایو بیز یکی از بهینهترین گزینهها برای موتورهای جستجو و فیلترهای امنیتی است. این مدل به خوبی میتواند احتمال تعلق یک سند متنی به یک موضوع خاص را محاسبه کند. به دلیل محاسبات ریاضی سبک، این الگوریتم در محیطهایی که منابع پردازشی محدودی دارند، به خوبی پاسخگوی نیاز کاربران خواهد بود.
کی نزدیک ترین همسایه
الگوریتم کی نزدیکترین همسایه بر اساس شباهت فیزیکی یا ریاضی بین نقاط داده کار میکند و بر این باور است که اشیاء مشابه معمولا در نزدیکی هم قرار دارند. زمانی که یک داده جدید وارد سیستم میشود، الگوریتم به تعداد مشخصی از نزدیکترین همسایههای آن نگاه کرده و بر اساس اکثریت آنها، برچسب جدید را تعیین میکند. این مدل در سیستمهای پیشنهادگر فیلم و موسیقی کاربرد فراوانی دارد و یادگیری آن ضروری است.

این الگوریتم به عنوان یک مدل تنبل شناخته میشود، زیرا مرحله آموزش طولانی ندارد و تمام محاسبات را در زمان پیشبینی انجام میدهد. سادگی در پیادهسازی باعث شده تا برای پروژههایی که دادههای آنها مدام در حال تغییر است، گزینه جذابی باشد.
خطا: کاربر درخواست HTTP را بلوکه نمود.
مدل های پیشرفته تجمعی و استخراج الگوهای پنهان در داده ها
مدلهای این بخش ترکیبی از مدلهای قبلی هستند و قدرت بیشتری در حل مسائل دشوار دارند. وقتی یاد گرفتید یک درخت تصمیم چگونه کار میکند، حالا وقت آن است که یاد بگیرید چگونه هزاران درخت را با هم ترکیب کنید تا به دقت بالاتری برسید. این بخش جایی است که قدرت واقعی انواع الگوریتم برای یادگیری ماشین در مدیریت حجم عظیم دادهها و انجام پیشبینیهای بسیار حساس نمایان میشود.
جنگل تصادفی
جنگل تصادفی از ترکیب تعداد زیادی درخت تصمیم ساخته میشود تا با همکاری یکدیگر، دقیقترین پیشبینی ممکن را به کاربر ارائه دهند. هر درخت به تنهایی ممکن است دچار خطا شود، اما وقتی هزاران درخت با هم رایگیری میکنند، خطای کلی مدل به شدت کاهش مییابد. این متد یکی از محبوبترین مدلها است زیرا به خوبی میتواند با دادههای از دست رفته کنار بیاید و از مشکلات پیچیده جلوگیری کند.
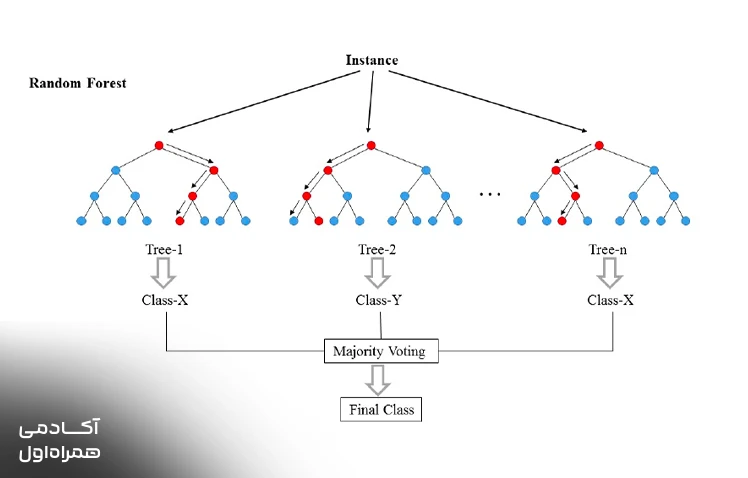
این الگوریتم در پیشبینیهای بازار سهام و تشخیص تقلبهای بانکی عملکرد بسیار درخشانی از خود نشان داده است. با استفاده از جنگل تصادفی، میتوان اهمیت هر ویژگی را در رسیدن به نتیجه نهایی اندازهگیری کرد.
تقویت گرادیان
در روش تقویت گرادیان، مدلها به صورت زنجیرهای ساخته میشوند و هر مدل جدید سعی میکند اشتباهات و نقاط ضعف مدل قبلی خود را اصلاح کند. این الگوریتم با تمرکز بر دادههایی که مدلهای قبلی در تشخیص آنها ضعیف بودهاند، دقت سیستم را به حداکثر ممکن میرساند. تکنولوژیهای پیشرفتهای مانند ایکس جی بوست که در مسابقات بزرگ علوم داده رتبههای برتر را کسب میکنند، بر پایه همین منطق طراحی شدهاند.
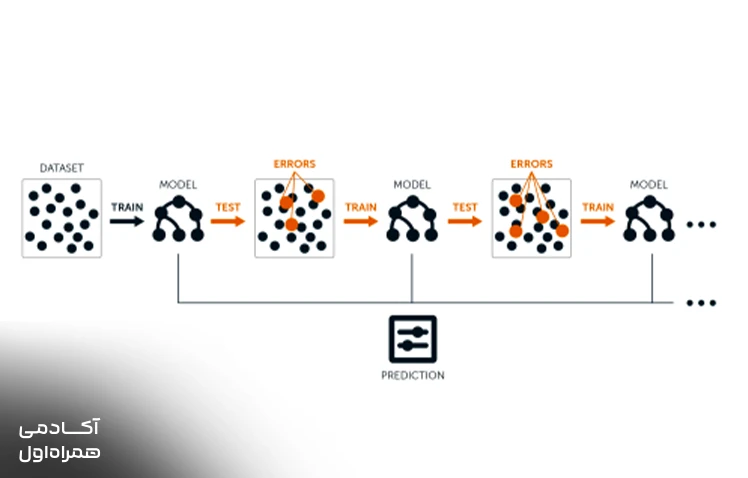
این مدل برای مسائلی که نیاز به دقت بسیار بالا دارند، مانند پیشبینی نرخ کلیک در تبلیغات آنلاین، بهترین انتخاب محسوب میشود. اگرچه زمان آموزش این مدل ممکن است کمی بیشتر از بقیه باشد، اما نتیجه نهایی معمولا بسیار دقیقتر و قابل اعتمادتر است. این الگوریتم به خوبی میتواند پیچیدهترین الگوهای غیرخطی را در مجموعههای داده بزرگ شناسایی و مدلسازی کند.
کی میانگین
الگوریتم کی میانگین ابزار اصلی در یادگیری نظارتنشده است که وظیفه خوشهبندی دادههای بدون برچسب را بر عهده دارد. این مدل با تکرار یک فرآیند ریاضی منظم، مرکز خوشهها را پیدا کرده و دادهها را به نزدیکترین مرکز اختصاص میدهد تا گروههای مشابه ایجاد شوند. از این روش برای بخشبندی مشتریان در بازاریابی استفاده میشود تا بتوان برای هر گروه، استراتژیهای تبلیغاتی متفاوتی طراحی کرد.
در میان انواع الگوریتم برای یادگیری ماشین، این متد برای فشردهسازی تصاویر و کاهش حجم دادهها نیز کاربرد دارد. شناسایی ناهنجاریها در شبکههای کامپیوتری و پیدا کردن الگوهای رفتاری عجیب در کاربران، از دیگر کاربردهای این مدل هوشمند است. کی میانگین به شما کمک میکند تا بدون داشتن دانش قبلی از برچسبها، ساختار درونی دادههای خود را کشف کنید.
آپریوری
الگوریتم آپریوری برای کشف قوانین پنهان در تراکنشهای بزرگ طراحی شده و به دنبال الگوهایی است که نشان میدهد خرید یک کالا، احتمال خرید کالای دیگری را بالا میبرد. این مدل با بررسی تکرار جفتشدن کالاها در سبدهای خرید، قوانین انجمنی ارزشمندی را برای صاحبان کسبوکار استخراج میکند. این ابزار برای چیدمان قفسههای فروشگاهی و طراحی پکیجهای تخفیفی بسیار حیاتی و پرکاربرد است.
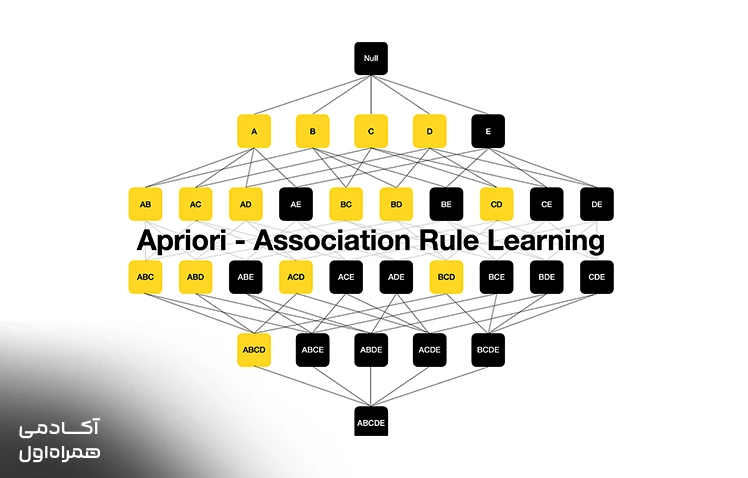
استفاده از این مدل در سیستمهای پیشنهاد خرید فروشگاههای اینترنتی باعث افزایش چشمگیر فروش شده است. آپریوری به عنوان یکی از کاربردیترین مدلها در میان انواع الگوریتم برای یادگیری ماشین، به تحلیلگران اجازه میدهد تا ارتباطات غیرمنتظره بین محصولات مختلف را کشف کنند.
جدول راهنمای کاربردی انواع الگوریتم برای یادگیری ماشین
دوستان عزیز در این بخش، خلاصهای از عملکرد و استفاده اصلی هر مدل به صورت طبقهبندی شده ارائه شده است تا درک بهتری حاصل شود:
| کاربرد کلیدی | دسته اصلی | نام الگوریتم |
| پیشبینی اعداد (مانند قیمت مسکن یا میزان فروش) | نظارتشده | رگرسیون خطی |
| طبقهبندی دوتایی (مانند تایید یا رد درخواست وام) | نظارتشده | رگرسیون لجستیک |
| تصمیمگیریهای منطقی و شفاف (مانند تعیین صلاحیت استخدام) | نظارتشده | درخت تصمیم |
| تفکیک دقیق دادههای پیچیده (مانند تشخیص چهره) | نظارتشده | ماشین بردار پشتیبان |
| دستهبندی سریع متن (مانند شناسایی ایمیلهای اسپم) | نظارتشده | نایو بیز |
| پیدا کردن موارد مشابه (مانند پیشنهاد فیلم به کاربر) | نظارت شده | کی نزدیکترین همسایه |
| پیشبینیهای دقیق و مقاوم (مانند تشخیص تقلب بانکی) | نظارت شده | جنگل تصادفی |
| مسابقات علوم داده و دقت حداکثری (مانند نرخ کلیک تبلیغات) | نظارت شده | تقویت گرادیان |
| گروهبندی دادههای خام (مانند بخشبندی مشتریان بازار) | نظارت نشده | کی میانگین |
| کشف روابط همزمانی (مانند تحلیل سبد خرید فروشگاهی) | نظارت نشده | آپریوری |
چرا انتخاب درست الگوریتم اهمیت دارد؟
بازار جهانی این حوزه با سرعتی باورنکردنی در حال رشد است و پیشبینی میشود ارزش آن در سالهای آینده به صدها میلیارد دلار برسد. انتخاب اشتباه از میان انواع الگوریتم برای یادگیری ماشین میتواند منجر به هدر رفتن بودجه و زمان زیادی در پروژههای صنعتی شود. برای شروع، همیشه اندازه دادهها و زمان مورد نیاز برای آموزش مدل را در نظر بگیرید و سپس اقدام به انتخاب نمایید.
متخصصان هوش مصنوعی بر این باورند که هیچ مدل جادویی واحدی وجود ندارد و بهترین گزینه، مدلی است که با نیاز تجاری شما همخوانی داشته باشد. علاوه بر این، کیفیت دادههای ورودی نقش تعیینکنندهای در عملکرد هر کدام از این روشها ایفا میکند. بنابراین، همیشه قبل از انتخاب نهایی، دادههای خود را به دقت بررسی و پاکسازی کنید تا به بهترین نتیجه برسید.
نقشه راه شروع یادگیری انواع الگوریتم برای یادگیری ماشین
برای شروع حرفهای در دنیای دادهها، باید مسیر را از نقطهای درست آغاز کنید تا در میان انبوه اطلاعات سردرگم نشوید. اولین و مهمترین قدم برای تسلط بر انواع الگوریتم برای یادگیری ماشین، یادگیری دقیق مفاهیم یادگیری نظارتشده و نظارتنشده است. این دو دستهبندی، پایه و اساس بیشتر پروژههای هوشمند امروزی را تشکیل میدهند.






